How to use Flask with gevent (uWSGI and Gunicorn editions)
如何在 Flask 中使用 gevent (uWSGI + Gunicorn 版本)
December 27, 2019 at 12:00 AM Asynchronous I/O
2019/12/27 12:00 异步 IO
Disclaimer: I wrote this tutorial because gevent saved our project a few years ago and I still see steady gevent-related search traffic on my blog. So, the way gevent helped us may be useful for somebody else as well. Since I still have some handy knowledge I decided to make this note on how to set up things. However, I’d not advise starting a new project in 2020 using this technology. IMHO, it’s aging and losing the traction.
免责声明:我当时写这篇教程是因为几年前 gevent 拯救了我们的项目,并且在我的博客上仍能看到有关 gevent 的稳定搜索流量。所以 gevent 帮助我们的方式可能对其他人也有用,因此我决定来记录下其实用的设置。然而,我不建议在2020年有新项目还使用这项技术,依本人愚见,它正在老化,失去了吸引力。
TL;DR: check out code samples on GitHub.
太长不看:在 Github 上查看代码示例
Python is booming and Flask is a pretty popular web-framework nowadays. Probably, quite some new projects are being started in Flask. But people should be aware, it’s synchronous by design and ASGI is not a thing yet. So, if someday you realize that your project really needs asynchronous I/O but you already have a considerable codebase on top of Flask, this tutorial is for you. The charming gevent library will enable you to keep using Flask while start benefiting from all the I/O being asynchronous. In the tutorial we will see:
如今 Python 爆炸式增长,Flask 作为一个相当受欢迎的 Web 框架,或许,许多新项目都采用了 Flask。但是人们应该知晓,同步设计和 ASGI 还不成气候。因此如果某天你意识到你的项目确实需要异步 I/O,并且你已经在 Flask 有最多的代码基准,看这篇教程就对了。明星库 gevent 将让你在持续使用Flask时从全异步 I/O 受益。在这篇教程中可以看到:
- How to monkey patch a Flask app to make it asynchronous w/o changing its code.
- How to run the patched application using gevent.pywsgi application server.
- How to run the patched application using Gunicorn application server.
- How to run the patched application using uWSGI application server.
- How to configure Nginx proxy in front of the application server.
[Bonus] How to use psycopg2 with psycogreen to make PostgreSQL access non-blocking.
如何修改代码给 Flask 应用打 猴子补丁 来让它支持异步 I/O
- 如何运行打过补丁使用 gevent.pywsgi 应用服务器的应用
- 如何运行打过补丁使用 Gunicorn 应用服务器的应用
- 如何运行打过补丁使用 uWSGI 应用服务器的应用
- 如何配置应用服务器前的 Nginx 代理
- [福利] 如何将 psycopg2 与 psycogreen 一起使用,来非阻塞访问 PostgreSQL
1. When do I need asynchronous I/O
The answer is somewhat naive - you need it when the application’s workload is I/O bound, i.e. it maxes out on latency SLI due to over-communicating to external services. It’s a pretty common situation nowadays due to the enormous spread of microservice architectures and various 3rd-party APIs. If an average HTTP handler in your application needs to make 10+ network requests to build a response, it’s highly likely that you will benefit from asynchronous I/O. On the other hand, if your application consumes 100% of CPU or RAM handling requests, migrating to asynchronous I/O probably will not help.
1. 什么时候需求异步 I/O
答案有些幼稚 — 当应用的工作负载受 I/O 限制时就需要它,即由于与外部服务的过度通信,它最大程度地增加了延迟 SLI (service level indicators,即服务水平指标)。由于微服务架构和各种第三方API的广泛传播,如今这是一种非常普遍的情况。如果你的应用中平均每个 HTTP Handler 需要调用 10 次以上的网络请求来生成响应,那么你就很有可能将从异步 I/O 中受益。换句话说,如果你的应用消耗 100% 的 CPU 或 RAM 来处理请求,那么迁移到异步 I/O 可能无济于事。
2. What is gevent
2. gevent 是什么
From the official site description:
来自官方站点的描述:
gevent is a coroutine-based Python networking library that uses greenlet to provide a high-level synchronous API on top of the libev or libuv event loop.
gevent 是一个基于协程的 Python 网络库,它使用 greenlet 在 libev 或 libuv 事件循环的顶层提供高级同步 API。
The description is rather obscure for those who are unfamiliar with the mentioned dependencies like greenlet, libev, or libuv. You can check out my previous attempt to briefly explain the nature of this library, but among other things it allows you to monkey patch normal-looking Python code and make the underlying I/O happening asynchronously. The patching introduces what’s called cooperative multitasking into the Python standard library and some 3rd-party modules but the change stays almost completely hidden from the application and the existing code keeps its synchronous-alike outlook while gains the ability to serve requests asynchronously. There is an obvious downside of this approach - the patching doesn’t change the way every single HTTP request is being served, i.e. the I/O within each HTTP handler still happens sequentially, even though it becomes asynchronous. Well, we can start using something similar to asyncio.gather() and parallelize some requests to external resources, but it would require the modification of the existing application code. However, now we can easily scale up the limit of concurrent HTTP requests for our application. After the patching, we don’t need a dedicated thread (or process) per request anymore. Instead, each request handling now happens in a lightweight green thread. Thus, the application can serve tens of thousands of concurrent requests, probably increasing this number by 1-2 orders of magnitude from the previous limit.
对于那些不熟悉所提及依赖项(例如greenlet,libev或libuv)的人来说,这个描述是相当晦涩的。你可以查看我先前的简要解释,但除此之外,通过打 猴子补丁 能让看上去很普通的 Python 代码在底层实现异步 I/O。补丁程序 将所谓的协作式多任务处理引入了 Python 标准库和一些第三方模块中,但是几乎完全隐藏应用程序中的改动,现有代码保持类似同步的外观,同时具有异步处理请求的能力。这种方法有一个明显的缺点 — 补丁不会改变每个 HTTP 请求被提供服务的方式,即每个 HTTP Handler 中的 I/O 仍然是顺序执行,即使它变成了异步。好了,我们可以开始使用类似于 asyncio.gather() 的东西,并将一些请求并行化到外部资源,但这将需要修改现有的应用程序代码。然而,现在我们可以轻松扩展应用的 HTTP 并发请求的限制。打完补丁后,我们不再需要每个请求一个专用线程(或进程)。相反,现在每个请求处理都在轻量级绿色线程中进行。因此,该应用程序可以处理成千上万的并发请求,可能让并发数限制比之前增加1-2个数量级。
However, while the description sounds extremely promising (at least to me), the project and the surrounding eco-system is steadily losing traction (in favor of asyncio and aiohttp?):
但是,尽管这个描述听起来非常有前途(至少对我来说),但是这个项目和它周围的生态系统正在逐渐失去吸引力(赞成使用 asyncio 和 aiohttp?):
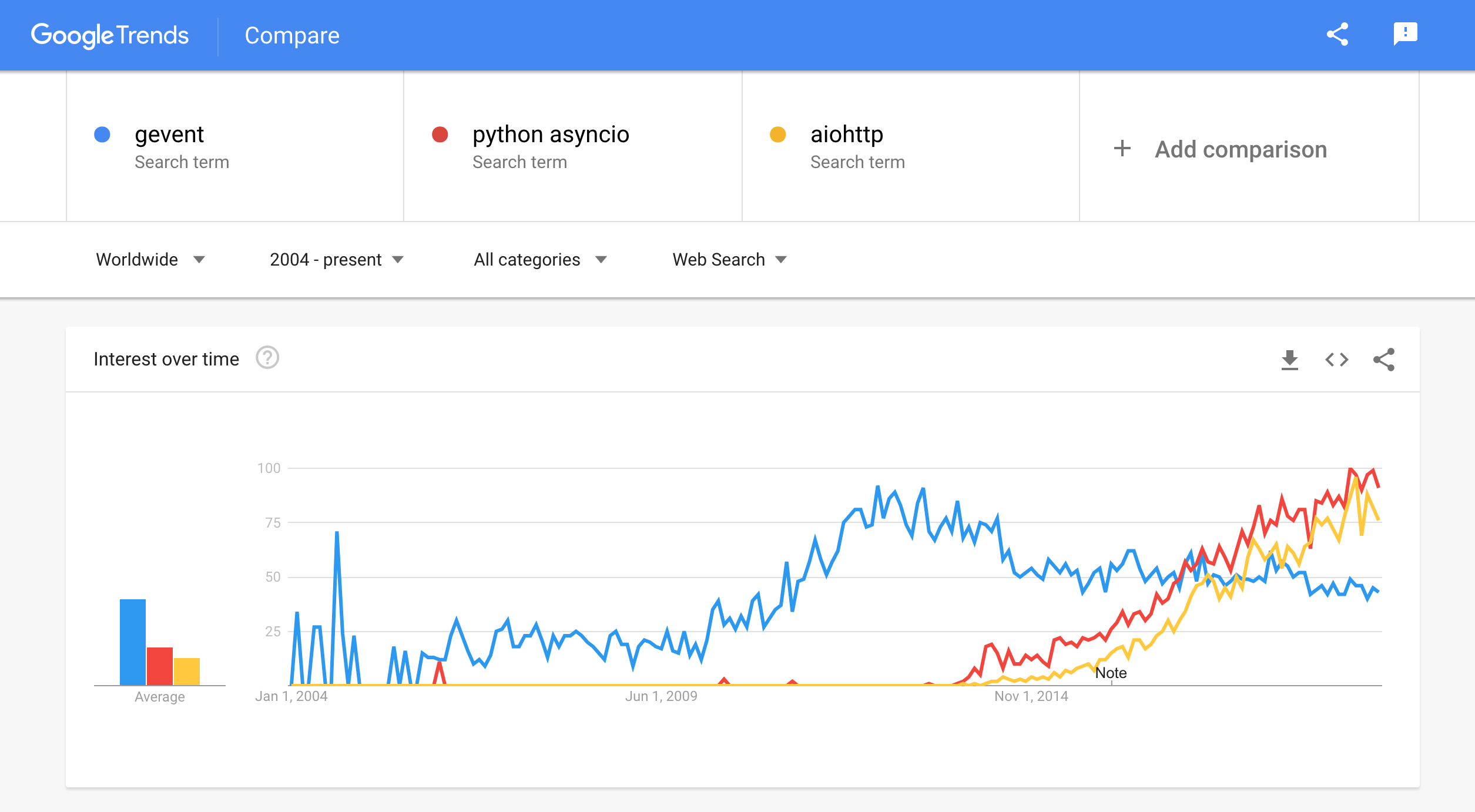
3. Create simple Flask application
3. 创建 Flask 单应用
The standard tutorial format always seemed boring to me. Instead, we will try to make a tiny playground here. We will try to create a simple Flask application dependant on a sleepy 3rd party API endpoint. The only route of our application will be responding with some hard-coded string concatenated with the API response text. Having such a workload, we will play with different methods of achieving high concurrency in the Flask’s handling of HTTP requests.
对我来说格式化的标准教程总是很无聊。相反,我们将尝试在此建立一个小型游乐场。我们将尝试创建一个基于第三方 API 端点的简单 Flask 睡眠应用。我们应用的唯一途径是将 API 响应文本与硬编码字符串连接起来作为响应。基于此,我们将使用不同的方法来实现 Flask 处理 HTTP 请求的高并发性。
First, we need to emulate a slow 3rd party API. We will use aiohttp to implement it because it’s based on the asyncio library and provides high concurrency for I/O-bound HTTP requests handling out of the box:
首先,我们需要模拟一个慢的第三方 API。我们将使用 aiohttp 来实现它,因为它基于asyncio库,并且开箱即用地为 I/O 绑定 HTTP请求 提供了高并发性:
|
|
We can launch it in the following Docker container:
我们可以在以下 Docker 容器中启动它:
|
|
Now, it’s time to create the target Flask application:
现在,是时候创建目标 Flask 应用了:
|
|
./flask_app/Dockerfile-devserver
FROM python:3.8
RUN pip install Flask requests
COPY app.py /app.py
ENV FLASK_APP=app
CMD flask run –no-reload \
–$THREADS-threads \
–host 0.0.0.0 –port $PORT_APP
./sync-devserver.yml
version: “3.7”
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-devserver
environment:
- PORT_APP=3000
- PORT_API=4000
- THREADS=without
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
flask_app_threaded: # extends: flask_app
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-devserver
environment:
- PORT_APP=3001
- PORT_API=4000
- THREADS=with
ports:
- "127.0.0.1:3001:3001"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
|
|
Build and start app served by Flask dev server
$ docker-compose -f sync-devserver.yml build
$ docker-compose -f sync-devserver.yml up
Test single-threaded deployment
$ ab -r -n 10 -c 5 http://127.0.0.1:3000/?delay=1
Concurrency Level: 5
Time taken for tests: 10.139 seconds
Complete requests: 10
Failed requests: 0
Requests per second: 0.99 [#/sec] (mean)
Test multi-threaded deployment
$ ab -r -n 2000 -c 200 http://127.0.0.1:3001/?delay=1
Concurrency Level: 200
Time taken for tests: 16.040 seconds
Complete requests: 2000
Failed requests: 0
Requests per second: 124.69 [#/sec] (mean)
./flask_app/pywsgi.py
from gevent import monkey
monkey.patch_all()
import os
from gevent.pywsgi import WSGIServer
from app import app
http_server = WSGIServer((‘0.0.0.0’, int(os.environ[‘PORT_APP’])), app)
http_server.serve_forever()
./flask_app/Dockerfile-gevent-pywsgi
FROM python:3.8
RUN pip install Flask requests gevent
COPY app.py /app.py
COPY pywsgi.py /pywsgi.py
CMD python /pywsgi.py
./async-gevent-pywsgi.yml
version: “3.7”
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-pywsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- THREADS=without
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
|
|
Build and start app served by gevent.pywsgi
$ docker-compose -f async-gevent-pywsgi.yml build
$ docker-compose -f async-gevent-pywsgi.yml up
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
Concurrency Level: 200
Time taken for tests: 17.536 seconds
Complete requests: 2000
Failed requests: 0
Requests per second: 114.05 [#/sec] (mean)
./flask_app/Dockerfile-gunicorn
FROM python:3.8
RUN pip install Flask requests gunicorn
COPY app.py /app.py
CMD gunicorn –workers $WORKERS \
–threads $THREADS \
–bind 0.0.0.0:$PORT_APP \
app:app
./sync-gunicorn.yml
version: “3.7”
services:
flask_app_gunicorn:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gunicorn
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=4
- THREADS=50
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
|
|
Build and start app served by Gunicorn
$ docker-compose -f sync-gunicorn.yml build
$ docker-compose -f sync-gunicorn.yml up
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
Concurrency Level: 200
Time taken for tests: 13.427 seconds
Complete requests: 2000
Failed requests: 0
Requests per second: 148.95 [#/sec] (mean)
./flask_app/patched.py
from gevent import monkey
monkey.patch_all() # we need to patch very early
from app import app # re-export
./flask_app/Dockerfile-gevent-gunicorn
FROM python:3.8
RUN pip install Flask requests gunicorn gevent
COPY app.py /app.py
COPY patched.py /patched.py
CMD gunicorn –worker-class gevent \
–workers $WORKERS \
–bind 0.0.0.0:$PORT_APP \
patched:app
./async-gevent-gunicorn.yml
version: “3.7”
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-gunicorn
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=1
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
|
|
Build and start app served by Gunicorn + gevent
$ docker-compose -f async-gevent-gunicorn.yml build
$ docker-compose -f async-gevent-gunicorn.yml up
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
Concurrency Level: 200
Time taken for tests: 17.839 seconds
Complete requests: 2000
Failed requests: 0
Requests per second: 112.11 [#/sec] (mean)
./flask_app/Dockerfile-uwsgi
FROM python:3.8
RUN pip install Flask requests uwsgi
COPY app.py /app.py
CMD uwsgi –master \
–workers $WORKERS \
–threads $THREADS \
–protocol $PROTOCOL \
–socket 0.0.0.0:$PORT_APP \
–module app:app
./sync-uwsgi.yml
version: “3.7”
services:
flask_app_uwsgi:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-uwsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=4
- THREADS=50
- PROTOCOL=http
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
|
|
Build and start app served by uWSGI
$ docker-compose -f sync-uwsgi.yml build
$ docker-compose -f sync-uwsgi.yml up
$ ab -r -n 2000 -c 200 http://127.0.0.1:3000/?delay=1
Concurrency Level: 200
Time taken for tests: 12.685 seconds
Complete requests: 2000
Failed requests: 0
Requests per second: 157.67 [#/sec] (mean)
./flask_app/Dockerfile-gevent-uwsgi
FROM python:3.8
RUN pip install Flask requests uwsgi gevent
COPY app.py /app.py
COPY patched.py /patched.py
CMD uwsgi –master \
–single-interpreter \
–workers $WORKERS \
–gevent $ASYNC_CORES \
–protocol $PROTOCOL \
–socket 0.0.0.0:$PORT_APP \
–module patched:app
./async-gevent-uwsgi.yml
version: “3.7”
services:
flask_app:
init: true
build:
context: ./flask_app
dockerfile: Dockerfile-gevent-uwsgi
environment:
- PORT_APP=3000
- PORT_API=4000
- WORKERS=2
- ASYNC_CORES=2000
- PROTOCOL=http
ports:
- "127.0.0.1:3000:3000"
depends_on:
- slow_api
slow_api:
init: true
build: ./slow_api
environment:
- PORT=4000
expose:
- "4000"
|
|
And do the test:
并且进行测试:
|
|
However, if we check the number of workers before and during the test we will notice a discrepancy with the previous method:
然而,如果我们检查在测试之前和测试期间的 workers 数量,我们会发现与之前的方法存在差异:
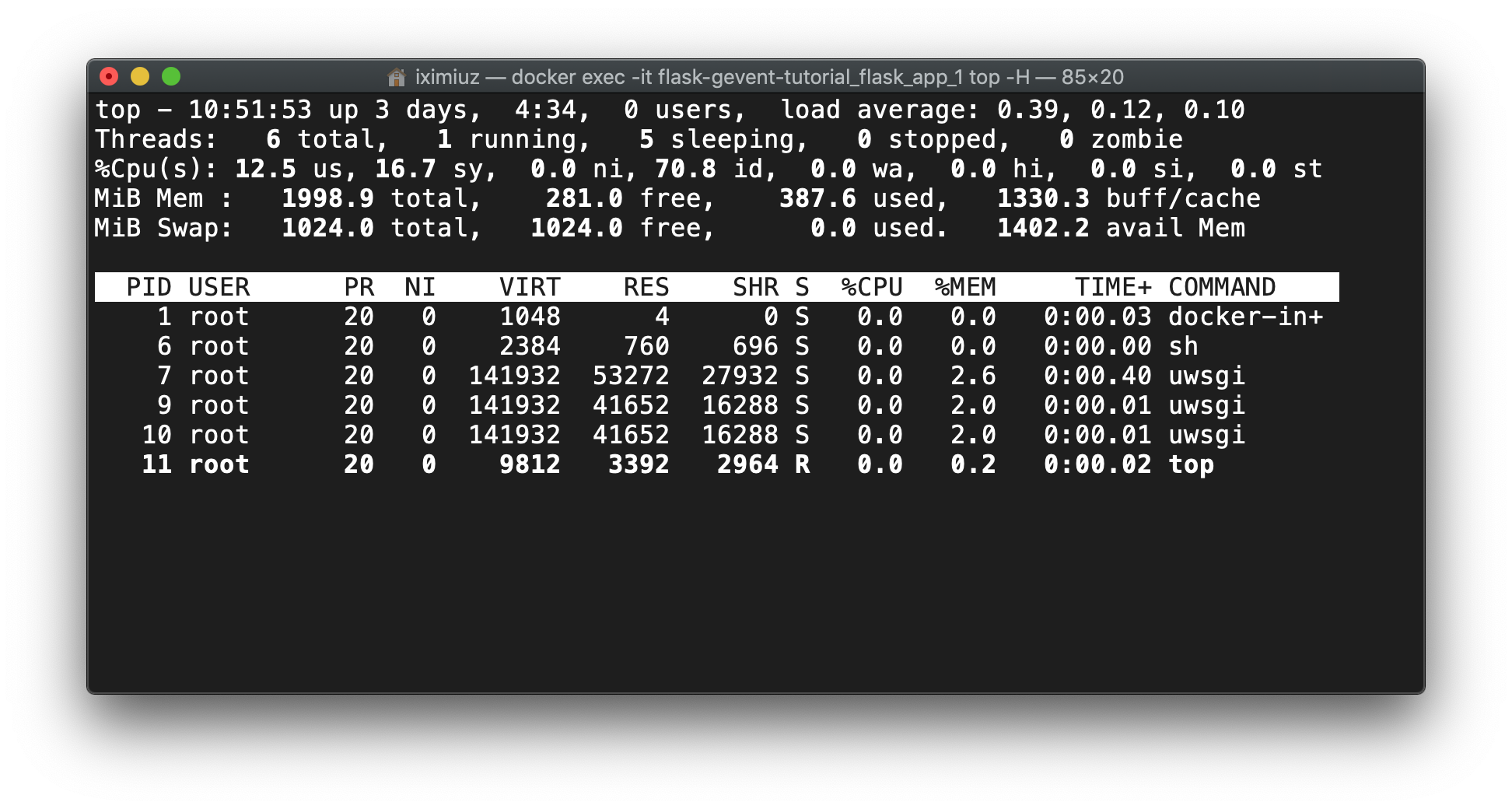
docker exec -it flask-gevent-tutorial_flask_app_1 top -H (before test)
Before the test, uWSGI had the master and worker processes only, but during the test, threads were started, somewhat around 10 threads per worker process. This number resembles the numbers from gevent.pywsgi and Gunicorn+gevent cases:
在测试之前,uWSGI只具有主进程和 worker 进程,但是在测试过程中,线程被启动了,每个 worker 进程大约有10个线程。这个数目与 gevent.pywsgi 和 Gunicorn + gevent 案例中的数目类似:
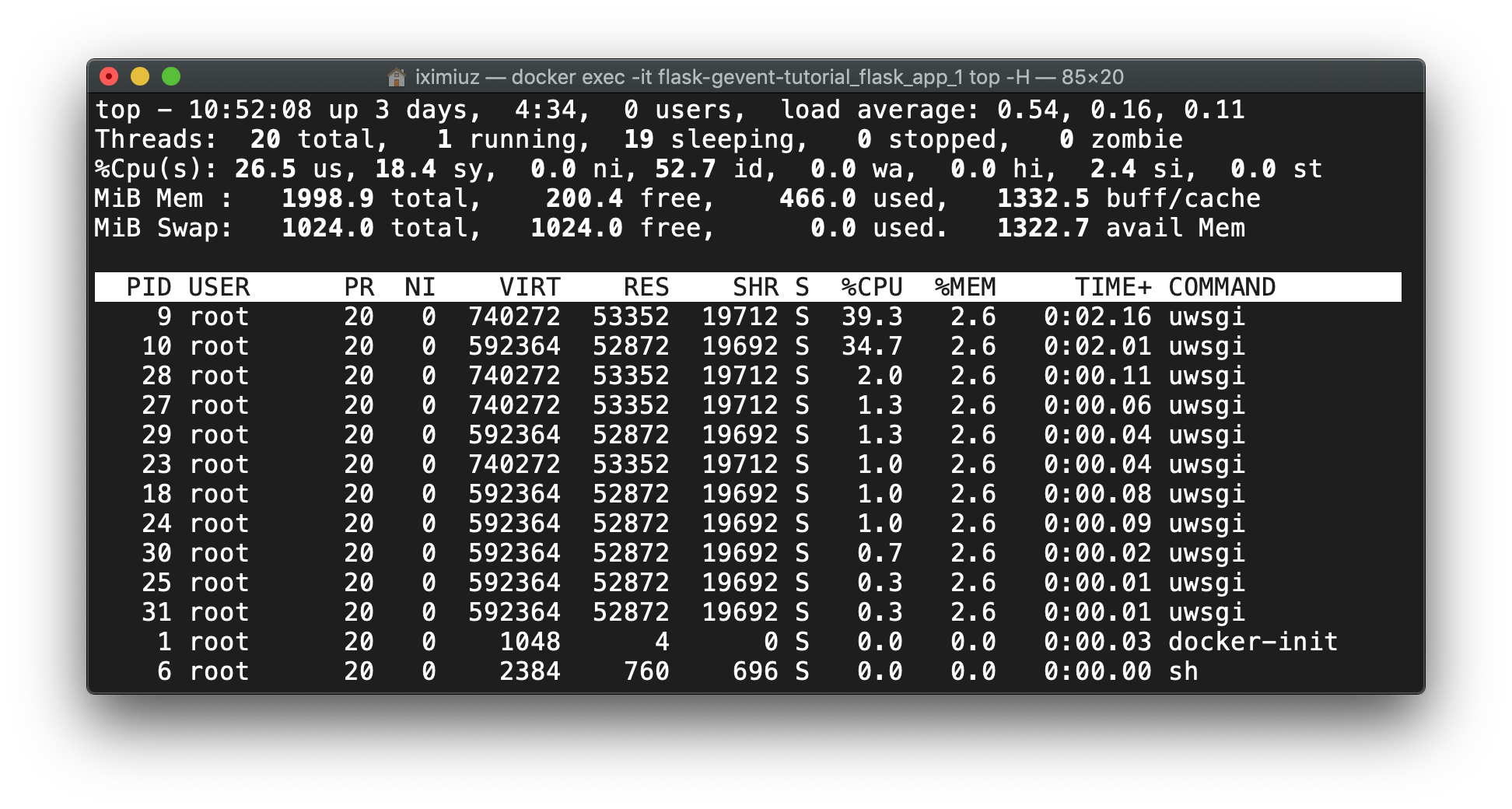
docker exec -it flask-gevent-tutorial_flask_app_1 top -H (during test)
8. Use Nginx reverse proxy in front of application server
8. 在应用服务器前使用 Nginx 反向代理
Usually, uWSGI and Gunicorn servers reside behind a load balancer and one of the most popular choices is Nginx.
通常,uWSGI 和 Gunicorn 服务器位于负载均衡器后面,最受欢迎的选择之一是 Nginx。
8.1 Nginx + Gunicorn + gevent
Nginx configuration for Gunicorn upstream is just a standard proxy setup:
Gunicorn 上游的 Nginx 配置只是一个标准的代理设置:
|
|
We can try it out using the following playground:
我们可以用下面的游乐场进行尝试:
|
|
And then:
然后:
|
|
8.2 Nginx + uWSGI + gevent
uWSGI setup is very similar, but there is a subtle improvement. uWSGI provides a special binary protocol (called uWSGI) to communicate with the reverse proxy in front of it. This makes the joint slightly more efficient. And Nginx kindly supports it:
uWSGI 的设置非常相似,但是有细微的改进。uWSGI 提供了一种特殊的二进制协议(称为uWSGI)与它前面的反向代理进行通信。这使得关节更加有效。Nginx对它的支持友好:
|
|
Notice the environment variable PROTOCOL=uwsgi in the following playground:
请注意下面游乐场中的环境变量 PROTOCOL = uwsgi:
|
|
We can test the playground using:
我们可以使用以下方法测试游乐场:
|
|
9. Bonus: make psycopg2 gevent-friendly with psycogreen
9. 福利:使用 psycogreen 让 psycopg2 变得 gevent 友好
When asked, gevent patches only modules from the Python standard library. If we use 3rd party modules, like psycopg2, corresponding IO will remain blocking. Let’s consider the following application:
gevent 仅支持对 Python 标准库中的模块打补丁。如果我们使用第三方模块(例如psycopg2),则相应的IO将保持阻塞状态。 让我们考虑以下应用:
|
|
We extended the workload by adding intentionally slow database access. Let’s prepare the Dockerfile:
通过有意地添加数据库慢访问,我们增加了工作负载。让我们准备 Dockerfile:
|
|
And the playground:
游乐场:
|
|
Ideally, we expect ~2 seconds to perform 10 one-second-long HTTP requests with concurrency 5. But the test shows more than 6 seconds due to the blocking behavior of psycopg2 calls:
理想情况下,在并发为5时,我们期望使用约2秒的时间来执行10个一秒长的HTTP请求。但是由于 psycopg2 调用的阻塞行为,该测试显示了超过6秒的时间:
|
|
To bypass this limitation, we need to use psycogreen module to patch psycopg2:
要绕过此限制,我们需要使用 psycogreen 模块来给 psycopg2 打补丁:
The psycogreen package enables psycopg2 to work with coroutine libraries, using asynchronous calls internally but offering a blocking interface so that regular code can run unmodified. Psycopg offers coroutines support since release 2.2. Because the main module is a C extension it cannot be monkey-patched to become coroutine-friendly. Instead it exposes a hook that coroutine libraries can use to install a function integrating with their event scheduler. Psycopg will call the function whenever it executes a libpq call that may block. psycogreen is a collection of “wait callbacks” useful to integrate Psycopg with different coroutine libraries.
psycogreen 软件包使 psycopg2 能够与协程库一起使用,在内部使用异步调用,但提供了阻塞接口,因此常规代码可以在未修改的情况下运行。自版本 2.2 起,Psycopg 提供协程支持。 由于主模块是 C 扩展,因此无法对其打猴子补丁来成为协程友好的。相反,它暴露了一个钩子,协程库可使用该钩子来安装与其事件调度程序集成的函数。只要 Psycopg 执行可能阻塞的libpq 调用,它将调用该函数。psycogreen 是“等待回调”的集合,可用于将 Psycopg 与不同的协程库集成在一起。
Let’s create an entrypoint:
让我们创建一个入口:
|
|
And extend the playground:
扩展游乐场:
|
|
If we test the new instance of the application with ab -n 10 -c 5, the observed performance will be much close to the theoretical one:
如果我们使用 ab -n 10 -c 5 测试应用的新实例,可以观察到其性能将非常接近理论值:
|
|
10. Instead of conclusion
10. 不是结论的结论
Make code, not war!
编写代码,而不是战争!
11. Related articles
11. 相关文章
Save the day with gevent
那天 gevent 拯救了我们
python,flask,gevent,asyncio,uwsgi,gunicorn,nginx
Written by Ivan Velichko
Follow me on twitter @iximiuz